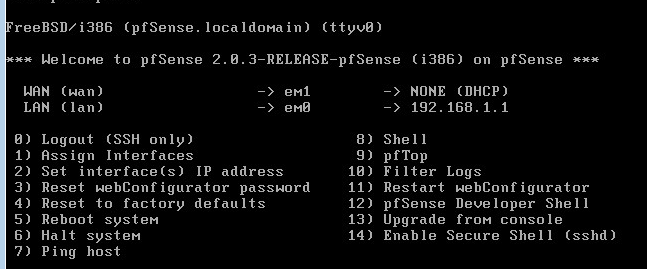
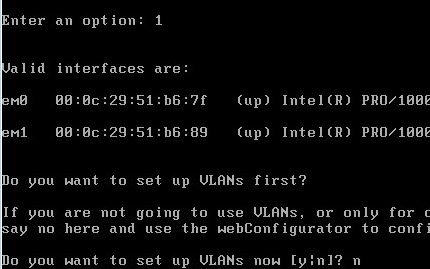
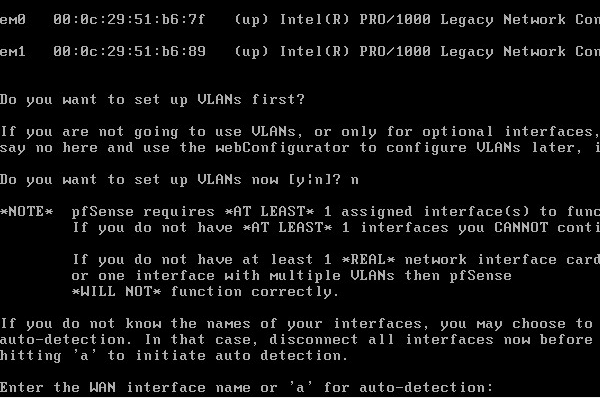
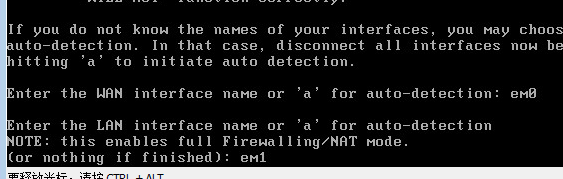
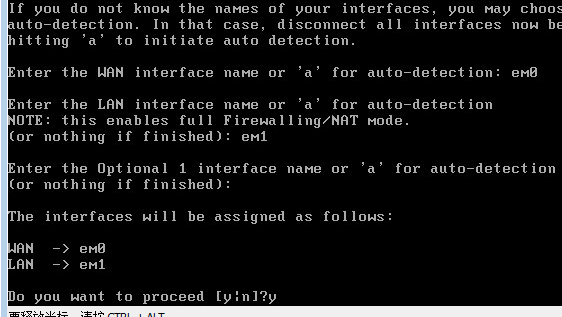
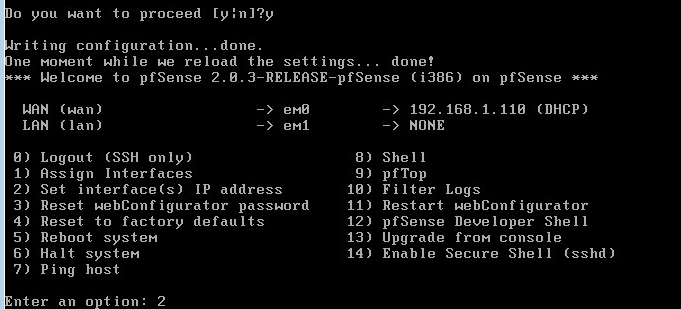
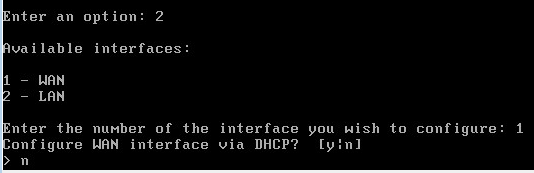
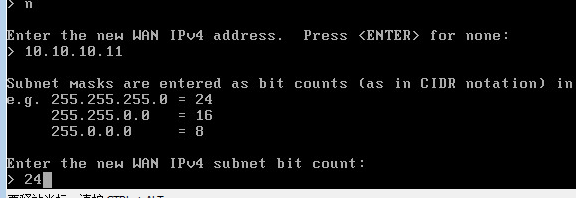
0x00
原文作者:Andreas Haas等 (Google), Dan Gohman等(Mozilla), Michael Holman(Microsoft),JF Bastien(Apple)
原文标题:Bringing the Web up to Speedwith WebAssembly
原文会议:PLDI 2017
Web平台的成熟引发了复杂和性能要求苛刻的Web应用程序,如交互式3D可视化,音频和视频软件以及游戏。因此,Web平台上代码的高效性和安全性变得越来越重要。然而,JavaScript作为Web平台(浏览器)唯一内置的语言,并不能很好地满足上述需求。
来自四大浏览器供应商(Google, Mozilla, Microsoft, Apple)的工程师已经面对这一挑战,合作设计了一个名为WebAssembly的可移植的底层字节码。它提供严谨的格式、有效的验证和编译、低或无开销安全执行。WebAssembly不针对特定的编程模型,而是对现代硬件的一层抽象,这使得WebAssembly和语言、硬件、平台无关,其平台也不仅仅局限于Web。WebAssembly从一开始就被设计为具有正式的语义。论文描述WebAssembly的动机,设计和形式语义,并提供一些实现的初步经验。论文的信息量很大,为了避免篇幅过长,本文只针对论文中提到的及基本思路以及效果进行着重介绍。
0x01 基本概念
文章在第一章首先介绍了WebAssembly的一些特性,即安全性、运行速度、可移植性,压缩性(WebAssembly二进制格式非常紧凑,对于通过网络传输的代码来说能够占用较小带宽,提升加载速度)。同时,文章也回顾了在浏览器中运行底层代码在过去的解决之道。例如Microsoft’s ActiveX,Native Client、Emscripten等等。接下来,作者介绍了WebAssembly的抽象语法,如图1所示。

图1 WebAssembly抽象语法
对应图1对抽象语法的表示,论文稍微详细介绍了其中的一部分。
1. 模块(Modules)
Modules定义了函数(functions)、全局变量(globals)、表(tables)、内存(memories)。Modules可以理解为“类”,Modules是静态的,但是模块可以实例化。实例化是由操作系统或JavaScript虚拟机进行的,Modules可以导入也可以导出。
2. 函数(Functions)
除了我们认识的函数之外,论文也解释了WebAssembly函数的一些特性。WebAssembly的函数不是头等函数(first-class function),通俗地讲,函数不能作为其他函数的参数,返回值,赋值给变量等等。但是WebAssembly函数具备嵌套、递归等基本的特性。
3. 指令(Instructions)
WebAssembly基于堆栈的虚拟机(另外一种流行的方法是基于寄存器的虚拟机),采用这种模式构造虚拟机是因为堆栈式虚拟机的二进制程序比寄存器式更紧凑(已经被证明)。由于类型系统,操作数堆栈布局可以在代码中任意位置静态确定,这对于在指令之间编译数据流非常方便,因为操作数堆栈布局可以在指令之间动态确定。
4. 陷阱(Traps)
有一些指令可能会产生陷阱,但是目前WebAssembly无法处理陷阱。嵌入在JavaScript中的WebAssembly会向JavaScript抛出异常,可以被JavaScript捕获和检查。
5. 机器类型(Machine Type)
WebAssembly只有4中基本类型,所有这些都可以被通用硬件支持。包括整数和IEEE 754浮点数,每个数字都是32位或64位宽。
6. 局部变量(Local Variables)
局部变量使用0作为初始化,并且分别通过get_local和set_local指令进行读取或写入。tee_local允许写入一个局部变量的同时在栈上留下一个输入值,这在实际代码中很常见。局部变量的索引空间以函数参数开头,这意味着函数参数也是可变的。
7. 全局变量(Global Variables)
模块可以声明全局变量,全局变量使用get_local和set_local指令去读写。虽然全局变量使用了变量(Variables)这个词,但是全局变量也可以是不变的(常量)。声明一个常量必须使用常量表达式。
0x02 线性内存和控制流
WebAssembly使用线性内存,主存储使用一个大字节数组进行组织。每个模块(Modules)可以定义自己内存,模块的内存可以通过导入导出与其他实例共享。内存使用初始大小创建,但是可以随需要动态增长。大小增长的单位是64KiB,这是现代计算机最小页面大小和最大页面大小的最小公倍数。这个页面允许重复使用,固定的大小也方便进行边界检查。
线性内存使用load和store指令进行访问,内存的访问是对齐的,这些指令采用静态对齐指数,正向静态偏移量,可选静态宽度以及动态i32地址进行组织,地址无符号整数。另外,WebAssembly的线性内存采用小端序(little-endian)进行组织。
为了保证安全性,线性内存和代码空间的数据结构不相交,也就是线性内存和代码空间完全在两个地方。编译的程序不能破坏其执行环境、跳到任意位置或其他未定义的行为。另外,快速的进程间隔离是WebAssembly与不可信JavaScript和Web API交互的设计约束,并且WebAssembly还允许在不违反内存安全的情况下将WebAssembly引擎嵌入到任何其他托管语言运行时中,并且允许具有自己内存的具有多个独立实例的程序存在于同一个进程中。
WebAssembly的结构化控制流突出的一个特性是不允许简单跳转,而只能使用结构化的方法(如break、continue)。
注:对于函数调用,导入导出表等方法,本文不进行过多叙述。
0x03 跨平台语义确定性
WebAssembly的一个目标就是在不牺牲代码性能的情况下,做到可移植,这就需要跨平台的语义确定性。在硬件不同的情况下,WebAssembly以最小的执行开销为所有硬件中的所有硬件提供了确定性语义。但是还是有三种特殊情况需要考虑。
1. NaN 值
NaN值在不同平台没有一个确定的标准,如果在每次数值操作后都进行NaN标准化开销又太大。因此WebAssembly使用了NaN-boxing技术来避免这一问题。
2. 资源枯竭
WebAssembly在不同平台运行时,由于平台差异,当试图增长线性内存时,一些平台可能会出现资源枯竭的情况。调用或调用间接指令也可能会遇到堆栈溢出,但这从WebAssembly本身内部不是可以观察到的。
3. 主机函数(Host Functions)
Host Functions可以理解为系统函数调用,可能会引起WebAssembly的状态变化,但是这不在WebAssembly语义可控范围之内。
0x04 执行
论文在对执行进行解释的时候使用了非常多离散数学表示方法。本文只进行一些粗浅的介绍。
执行相对于全局存储来进行,存储是已分配的模块实、表和内存的存储记录。列表中的索引可以被认为是地址,函数的运行时采用闭包来表示。模块的实例需要被转化为实体记录,转化方法如图2所示。

图2 运行时对象表示语法
为了得到更紧凑的执行规则,同时避免引入操作数和堆栈的单独概念,采用小步缩减(Small-Step)的方式来缩减规则。缩减方法如图3所示。

图3 小步缩减规则
0x05 嵌入和互操作性
WebAssembly类似于虚拟的指令集架构(ISA),它没有定义程序如何加载到执行引擎和I / O操作的方法,这种分离设计(嵌入器不由WebAssembly实现)是为了将WebAssembly顺利嵌入到执行环境当中去。而嵌入器定义了模块如何加载,模块之间的导入和导出如何解析,并提供外部函数来完成I / O操作和计时器,并指定如何处理WebAssembly的陷阱(异常)。论文中的主要用例是浏览器JavaScript的嵌入,这些机制是通过JavaScript和Web API实现的。
1. JavaScript API
通过浏览器中的JavaScript API加载,编译和调用WebAssembly模块。粗略的方法是:
1)从给定源(如网络或磁盘)获取二进制模块
2)实例化模块,提供必要的导入
3)调用所需的导出函数
由于编译和实例化可能很慢,所以用异步方法进行上述处理,其结果包含在JavaScript Promise中。
2. 链接
链接嵌入程序可以实例化多个模块,并使用导出到另一个模块的导出模块。实例之间可以彼此调用对方的函数,共享内存或共享函数和表。导入的全局变量可以作为链接的配置参数。在浏览器中,JavaScript API还允许在外部创建和初始化内存或表,或访问导出的内存和表。它们被表示为专用JavaScript类的对象,每个内存都由标准的ArrayBuffer支持。
3. 相互操作性
链接不同的人编写出的模块是可能的,但是作为低级语言,WebAssembly不提供任何内置对象模型。开发人员需要将他们的数据类型映射为数(numbers)或内存(memories)。这种设计为开发人员提供了最大的灵活性。另外,尽管WebAssembly具有编程语言形式,但是它是对硬件的抽象,而不是对编程语言的抽象,因此与之前的虚拟机不同,WebAssembly不授予任何编程语言编程和对象模型的特殊待遇或是对某些编程语言进行遏制(也就是说任何编程语言都可以编译为WebAssembly,只要编译器针对WebAssembly抽象硬件进行设计)。
开发人员还可以在WebAssembly之上定义常见的ABI,以便模块可以在不同种类的应用程序中相互操作。这种分离方式对于使WebAssembly成为通用的代码格式至关重要。
0x06 实现
WebAssembly的一个主要设计目标是高性能,又能不牺牲安全性或可移植性。 在整个设计过程中,论文的作者们(四大主流浏览器厂商的工程师们)在所有主流浏览器中开发了WebAssembly的独立实现,以验证和通知设计决策,这一节中主要介绍一些有趣的实现的点。
1. 四大浏览器引擎的实现方案
V8(Google Chrome中的JavaScript引擎),Spider-Monkey(Mozilla Firefox中的JavaScript引擎)和JavaScriptCore(WebKit中的JavaScript引擎)在实例化之前重新使用其优化的JIT编译器来提前编译模块。这实现了可预测的高峰值性能,并且避免了热身时间(也就是热启动时间)的不可预测性,而这对JavaScript来说常常是一个问题。
而微软的Chakra(查克拉,Microsoft Edge中的JavaScript引擎)在第一次执行时离散地将单个函数翻译为解释后的内部字节码格式,然后JIT编译最热门的函数。 这种方法的优点是更快的启动速度和更低的内存消耗。我们预计更多实现方案会随着时间的推移而发展。
2. 快速验证
本文中没有选取论文中关于验证的部分,有兴趣的朋友可以查看可以去原文第4章Validation中查看WebAssembly快速验证代码方案。
WebAssembly的关键设计目标是快速验证代码。 在上述四个实现中,使用了抽象控制堆栈,具有类型的抽象操作数堆栈和前向程序计数器的相同基本策略。 验证是通过即时检查传入字节码进行的,没有构建中间表示。我们在现代工作站上的一套代表性基准测试中测量的单线验证速度在75 MiB / s和150MiB / s之间。 这大约能够以1吉比/秒的全网速度下执行验证。
3. 底线JIT编译器(Baseline JIT Compiler)
Mozilla的SpiderMonkey引擎包含两个WebAssembly编译层。 第一个是WebAssembly特定的快速Baseline JIT,它与验证结合,在一次发送中发出机器代码。 JIT在编译期间不会创建内部中间表示(IR),但会跟踪寄存器状态并尝试在正向通道中执行简单的贪婪寄存器分配。 Baseline JIT仅用于快速启动,而Ion优化JIT则在后台并行编译模块。 Ion JIT也被SpiderMonkey用作JavaScript的顶层。
4. 优化JIT编译器(Optimizing JIT Compiler)
V8,SpiderMonkey,JavaScript-Core和Chakra都包括优化JIT,以实现WebAssembly的最高峰值性能。 V8和Spider-Monkey顶级JIT都使用基于静态单赋值形式(SSA)的中间表示(IR)。因此,重要的是要验证WebAssembly可以在单一线程中解码为SSA格式,以供给这些JIT。
0x07 性能测试
论文首先以本机代码(Native Code,使用Clang生成)的运行时间为基准,使用PolyBenchC对WebAssembly(使用Emscripten生成)进行了性能测试,测试结果如图2所示。在这张图里使用Native Code运行时间做归一化,所以100%的一条横线是Native Code的运行时间,Native Code是用Clang编译的真正的二进制程序,WebAssembly有4中情况运行速度更快,7种情况最多没有超过Native Code 的10%,而大部分情况是没有超过Native Code的200%的,这个性能对于运行在V8和SpiderMonkey浏览器引擎里的代码来说,已经非常快了。
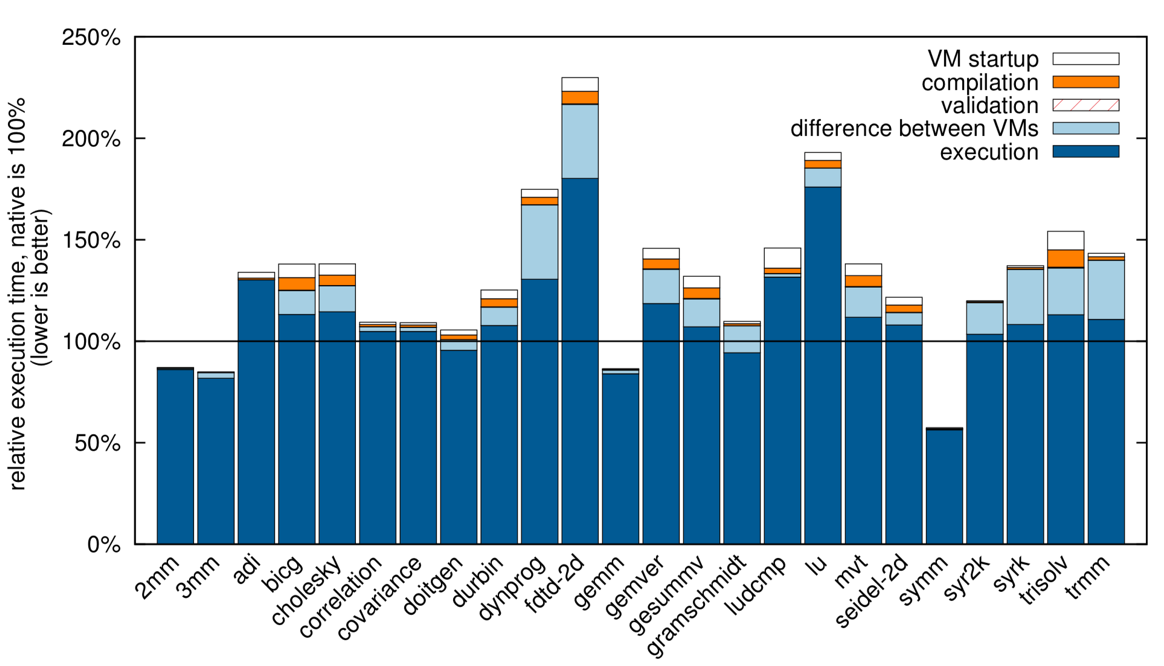
图4 WebAssembly与Native Code运行时间对比
对于WebAssembly和asm.js的速度对比,论文没有进行画图比较,作者提到了WebAssembly相较于asm.js快了33.7%。另外,对于代码的紧凑性,实验也进行了比较。论文比较了WebAssembly和asm.js,以及WebAssembly和x86-64本机代码(Native Code)。结果如图5所示。
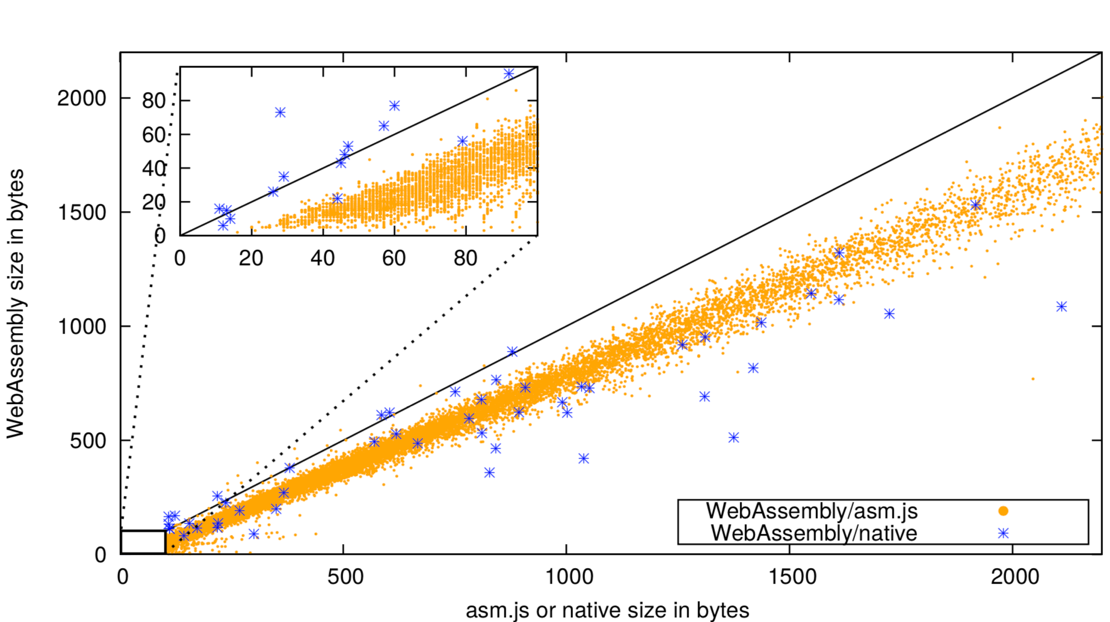
图5 WebAssembly与asm.js和NativeCode二进制大小对比
平均来说,WebAssembly代码是asm.js的大小的62.5%(中位数68.6%),以及本机x86-64代码大小的85.3%(中位数78%)。
0x08 总结
论文中提出的新技术已经在四大主流浏览器引擎中得到了实现。虽然WebAssembly于2017年11月开始受到四大主流浏览器支持,到现在也仅仅过去半年,还有很多需要完善的地方。但是WebAssembly是Web的一个新趋势,其更加广泛的应用势必会给Web带来新的能力和发展空间,同时可能也会为Web安全带来一个全新的领域。